Get Certified for
Business Intelligence (BIDA®)
Develop analytical superpowers by learning how to use programming and data analytics tools such as VBA, Python, Tableau, Power BI, Power Query, and more.
The required background knowledge of the field to which the methods of data science are being applied
In data science, the term domain knowledge is used to refer to the general background knowledge of the field or environment to which the methods of data science are being applied. Data science, as a discipline, can be thought of as the study of tools used to model data, generate insights from data, and make decisions based on data. They are generic tools applicable to many fields such as engineering, laws, medicine, finance, etc.
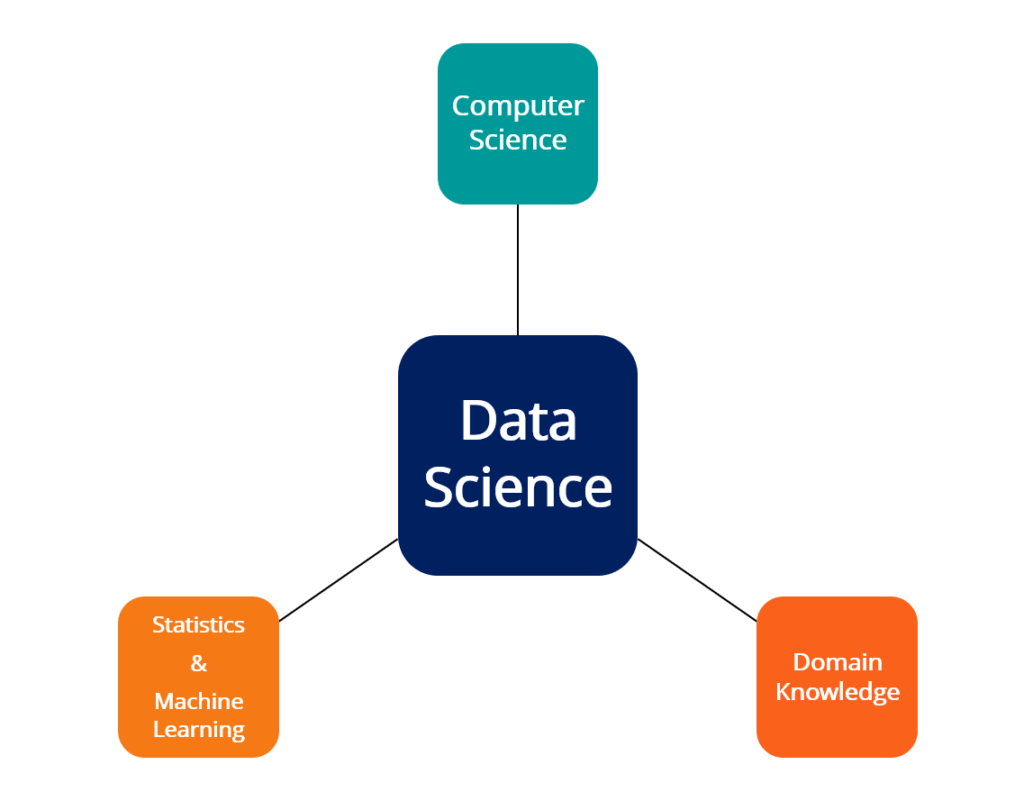
Broadly speaking, data science comprises of the three main subject areas:
Computational science and programming refer to the study of computational tools like programming languages, software libraries, and other tools. The knowledge of programming is essential for anyone who wishes to apply data science to problems in their field.
Statistics and machine learning form the theoretical foundations of data science methods and algorithms. An understanding of the theoretical underpinnings of data science is required to know the limits of the methods being applied, as well as to interpret the results of the data science process properly.
Domain knowledge is often referred to as a general discipline or field to which data science is applied to. An expert or specialist in a field such as biotech is said to possess domain knowledge of that industry.
The first two items in the list above are essential skills that are required by all practitioners of data science and are common to all applications of data science regardless of the domain.
On the other hand, domain knowledge is more specialized. The lack of domain knowledge makes it difficult to apply the right methods as well as to judge their performance properly. In fact, the application of domain knowledge must be pervasive throughout the data science process in order for it to be effective.
Here, we will discuss how domain knowledge applies to every part of the data science process. The data science process can be divided into four sub-processes as described below. The following figure summarizes the data science process:
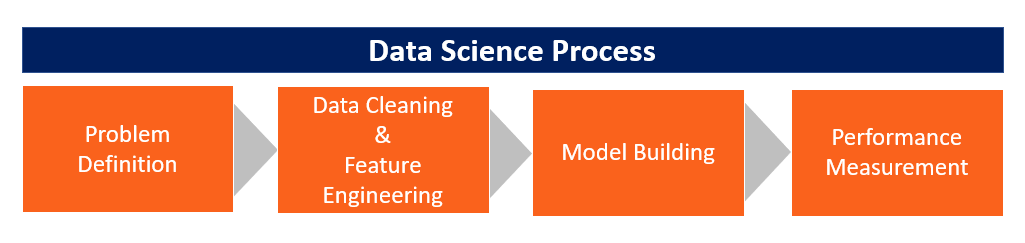
The first step in any data science is defining the problem to be solved. It starts from a generic description of the problem and involves defining desired performance criteria.
Defining the problem is an easy step for a simple problem like predicting credit default, where the problem definition is simply predicting the probability of default based on the data on past borrowers. On the other hand, consider a problem in robotics or medicine, where a person without any domain knowledge cannot even define the pattern they are looking for in the data.
Most data collected in any field is seldom clean and ready for use. The process of preparing the data for the modeling process is data cleaning and feature engineering. Data cleaning and feature engineering involve transforming the data. Incorrectly transformed data can lead to spurious results.
For example, while analyzing the relationship between, say stock price and financial results like cash flows, one might scale down cash flows. However, the scaling would introduce a look-ahead bias in the data as the naïve scaling process will use future data to scale past data. It will lead to spurious results in any analysis based on incorrectly transformed data.
Further, domain knowledge is required in choosing the correct features from the data, which will provide the most predictive power.
The model-building step involves fitting a model to data. The model built here is used to solve the problem defined in the first step. The choice of an appropriate model is essential to the success of the data science process. Again, this choice depends on the field of application and is enhanced by strong domain knowledge.
Performance measurement is the final step in the data science process that involves measuring how the model performs on new data or out of sample data, which was not used while building the model. The choice of performance metrics and thresholds is primarily driven by domain knowledge.
For example, when building a model to predict credit defaults, a false negative (predicting a potential defaulter to be in good credit) is costlier than a false positive (predicting a non-defaulter to be a defaulter). Such asymmetries will be different across disciplines, and it would be hard to detect them without domain knowledge. Further computing the costs from model failure can only be accurately estimated by a person with domain knowledge.
In this section, we will look at a case study that illustrates the importance of domain knowledge. Predicting credit card delinquency is a common problem in consumer finance, where a credit card provider must decide whether to issue credit cards to a particular customer. It also helps the provider make risk assessments and strategic decisions.
We will look at a small data science project that aims to predict delinquency in credit card customers. The data consists of about 100,000 individual customers with data on 10 attributes, including one indicating whether the customer was delinquent. Beginning with the problem definition, we will go through the various steps involved in the data science process as described above.
Step 1: Problem Definition
In this case, the problem is easy to define. Predict the value of the delinquency indicator.
Step 2: Data Cleaning and Feature Engineering
Data cleaning and feature engineering is an important part of the process in our case. The reason behind this is that the data is imbalanced, meaning that it does not have an equal representation of delinquents and non-delinquents.
In fact, the data has 93% non-delinquents, which is expected in the real world as most people do not default on their credit card debt. This imbalance can affect the choice of model and performance metric used. It will also affect the quality of the model.
A domain expert in credit risk would be aware that such an imbalance would create the need for methods to tackle the issue. A simple solution would be to resample the data, which creates a balanced but smaller dataset. This trade-off between the quality and quantity of data requires domain knowledge to identify and adjust.
Step 3: Model Building
When building a model for predicting credit delinquency, a domain expert would be familiar with past approaches to the problem. In this case, the literature includes extensive use of logistic regression. Thus, it can provide a good starting point for model selection and a baseline to benchmark new approaches.
Step 4: Performance Measurement
Selecting good performance measurement criteria is a critical step in developing a credit risk model, as an incorrect metric can lead to a wrong model being selected. In our case, where the data is imbalanced, a naïve model that labels all customers as non-delinquents will have very high accuracy, but in the process, it may label all defaulters as non-delinquents as well.
Such a problem requires a model that predicts most of the defaulters correctly while misidentifying only a few non-delinquents. It should be reflected in the performance metric. Further, in this case, mislabeling a delinquent customer is costlier than mislabeling a non-delinquent, and such a trade-off requires a proper understanding of the costs and risks involved. It cannot be a completely objective decision based on a singular metric and subjective judgment based on domain knowledge is required.
Thank you for reading CFI’s guide to Domain Knowledge (Data Science). To keep learning and developing your knowledge base, please explore the additional relevant resources below: