Get Certified for
Business Intelligence (BIDA®)
Develop analytical superpowers by learning how to use programming and data analytics tools such as VBA, Python, Tableau, Power BI, Power Query, and more.
A process or a set of practices that ensures the security, accuracy, and overall quality of data
Data integrity is a process or a set of practices that ensures the security, accuracy, and overall quality of data. It is a broad concept that includes cybersecurity, physical safety, and database management.
The following diagram summarizes the main components of data integrity:
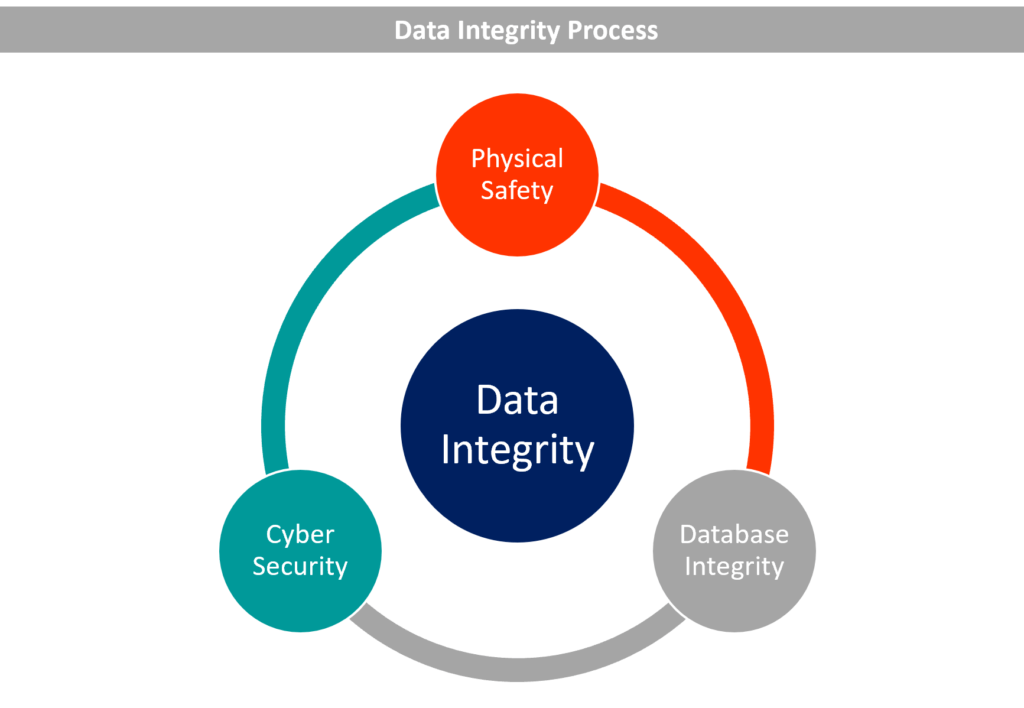
Physical safety ensures that the devices on which the data is stored are safe from weather, fire, theft, and similar events. It also includes ensuring the quality of devices that store the data. Faulty devices can lead to an unexpected loss of data.
To mitigate such a risk, sometimes the same data is stored in multiple locations and data centers. The redundancy helps the continuity of operations in the event of unexpected data loss.
Another aspect of physical safety is creating copies and backups of the data to other locations without errors or gaps. It is accomplished by using specialized algorithms known as hash functions. Simply put, if two pieces of data are the same, they provide the same output when processed using a hash function. Such a comparison helps ensure that the data is transferred properly.
Cybersecurity mostly revolves around who can access the data. Only authorized personnel and programs should be allowed to view or modify the data. Otherwise, the data will be corrupted either by malicious behavior or in error.
Cybersecurity uses credentials like usernames and passwords to restrict access to data. In some cases, the data may even be encrypted, so even if it is leaked or stolen, it will not be used without a decryption key.
Databases usually come with a defined structure that helps define the relationship between different types of data. They are implemented via entity relationships (foreign keys) and constraints encoded into the tables at the time of creation.
There are several different constraints available in SQL that can be used to perform data validation at the time of data entry. Some of the constraints include:
The checks above are all used to maintain the consistency, accuracy, and logical integrity of the data.
Ensuring a high level of data quality is a part of the data integrity process. It involves carrying out regular data checks that ensure that the data meet a certain standard. Data quality assurance includes the processes of data cleaning, data accessibility, and data standardization.
Data cleaning involves removing invalid entries, imputing missing data, and properly dealing with outliers. Data accessibility ensures that data is made available to all stakeholders in a secure and timely manner. Data standardization is the process of laying down business rules for encoding and entering data. These rules are also used to enforce company policy and legal regulations.
Data corruption is the failure of data integrity practices and processes. There are various channels through which data corruption may occur. They include human error, malware, and physical damage.
Human error is where data is corrupted due to mistakes in data entry, programming, and unauthorized access. It can be countered with proper data validation checks and restricting access to data. Extensive and regular use of backups can help restore databases in case of incorrect entries.
Malware is an external attack that may lead to data being stolen. Cyberattacks are almost always unforeseen. Therefore, it is always prudent to encrypt critical data and impose tight controls around data access. Regular penetration testing is good practice to ensure that organizational networks are secure.
There is always a small chance that data is lost due to physical damage caused by accidents and disasters. A good way to protect against a permanent loss of data is to house the data in separate data centers in geographically distant locations.
Connect what you just learned to a clear career path with CFI’s role‑based courses and certification programs.
Thank you for reading CFI’s guide to Data Integrity. To keep advancing your career, the additional CFI resources below will be useful:





