Get Certified for
Business Intelligence (BIDA®)
Develop analytical superpowers by learning how to use programming and data analytics tools such as VBA, Python, Tableau, Power BI, Power Query, and more.
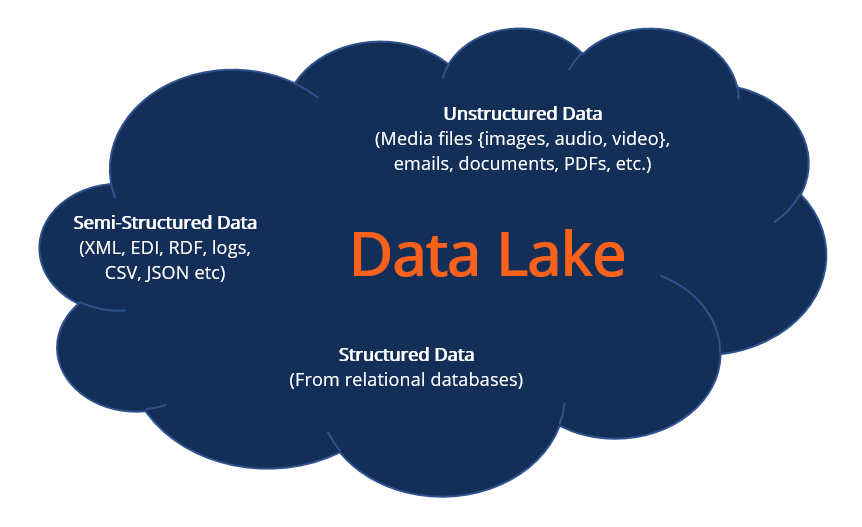
A central storage repository used to store a vast amount of raw, granular data in its native formatData Lake
A data lake refers to a central storage repository used to store a vast amount of raw, granular data in its native format. It is a single store repository containing structured data, semi-structured data, and unstructured data.
A data lake is used where there is no fixed storage, no file type limitations, and emphasis is on flexible format storage for future use. Data lake architecture is flat and uses metadata tags and identifiers for quicker data retrieval in a data lake.
The term “data lake” was coined by the Chief Technology Officer of Pentaho, James Dixon, to contrast it with the more refined and processed data warehouse repository. The popularity of data lakes continues to grow, especially in organizations that prefer large, holistic data storage.
Data in a data lake is not filtered before storage, and accessing the data for analysis is ad hoc and varied. The data is not transformed until it is needed for analysis. However, data lakes need regular maintenance and some form of governance to ensure data usability and accessibility. If data lakes are not maintained well and become inaccessible, they are referred to as “data swamps.”
Data lakes are often confused with data warehouses; hence, to understand data lakes, it is crucial to acknowledge the fundamental distinctions between the two data repositories.
As indicated, both are data repositories that serve the same universal purpose and objective of storing organizational data to support decision-making. Data lakes and data warehouses are alternatives and mainly differ in their architecture, which can be concisely broken down into the following points.
The schema for a data lake is not predetermined before data is applied to it, which means data is stored in its native format containing structured and unstructured data. Data is processed when it is being used. However, a data warehouse schema is predefined and predetermined before the application of data, a state known as schema on write. Data lakes are termed schema on read.
Data lakes are flexible and adaptable to changes in use and circumstances, while data warehouses take considerable time defining their schema, which cannot be modified hastily to changing requirements. Data lakes storage is easily expanded through the scaling of its servers.
Accessibility of data in a data lake requires some skill to understand its data relationships due to its undefined schema. In comparison, data in a data warehouse is easily accessible due to its structured, defined schema. Many users can easily access warehouse data, while not all users in an organization can comprehend data lake accessibility.
Storing data in a data lake for later processing when the need arises is cost-effective and offers an unrefined view to data analysts. The other reasons for creating a data lake are as follows:
A data lake architecture can accommodate unstructured data and different data structures from multiple sources across the organization. All data lakes have two components, storage and compute, and they can both be located on-premises or based in the cloud. The data lake architecture can use a combination of cloud and on-premises locations.
It is difficult to measure the volume of data that will need to be accommodated by a data lake. For this reason, data lake architecture provides expanded scalability, as high as an exabyte, a feat a conventional storage system is not capable of. Data should be tagged with metadata during its application into the data lake to ensure future accessibility.
Below is a concept diagram for a data lake structure:
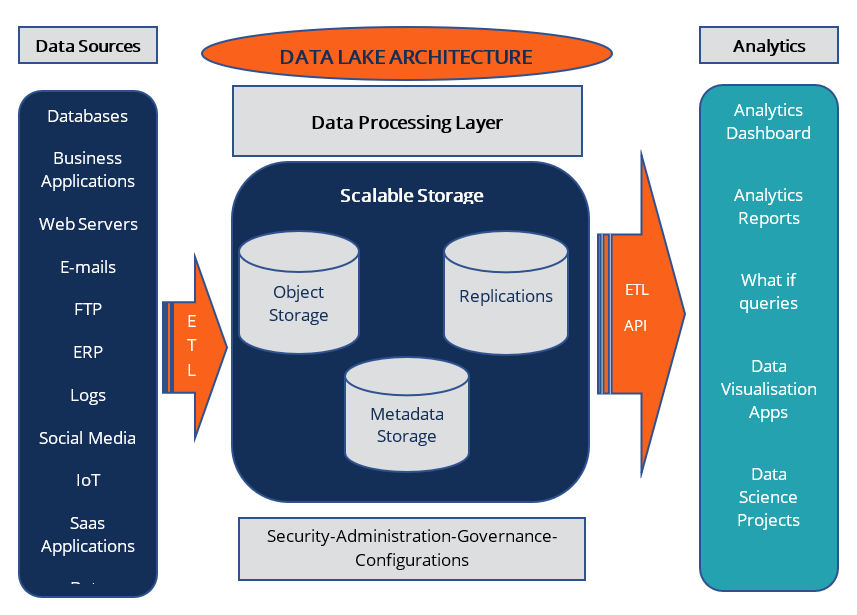
Data lakes software such as Hadoop and Amazon Simple Storage Service (Amazon S3) vary in terms of structure and strategy. Data lake architecture software organizes data in a data lake and makes it easier to access and use. The following features should be incorporated in a data lake architecture to prevent the development of a data swamp and ensure data lake functionality.
We have singled out illustrating Hadoop data lake infrastructure as an example. Some data lake architecture providers use a Hadoop-based data management platform consisting of one or more Hadoop clusters. Hadoop uses a cluster of distributed servers for data storage. The Hadoop ecosystem comprises three main core elements:
Hadoop supplementary tools include Pig, Hive, Sqoop, and Kafka. The tools assist in the processes of ingestion, preparation, and extraction. Hadoop can be combined with cloud enterprise platforms to offer a cloud-based data lake infrastructure.
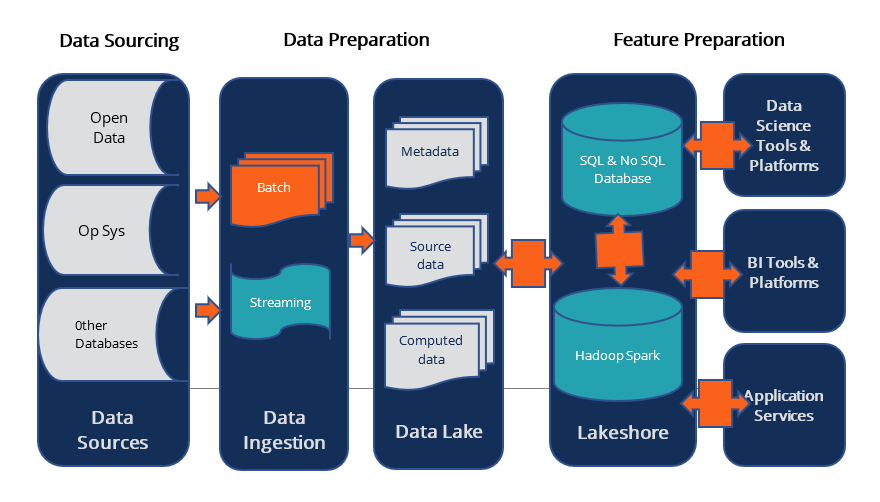
Hadoop is an open-source technology that makes it less expensive to use. Several ETL tools are available for integration with Hadoop. It is easy to scale and provides faster computation due to its data locality, which has increased its popularity and familiarity among most technology users.
Below are some key data lake concepts to broaden and deepen the understanding of data lakes architecture.
Popular data lake technology providers include the following:
To keep learning and developing your knowledge base, please explore the additional relevant resources below:





