Get Certified for
Business Intelligence (BIDA®)
Develop analytical superpowers by learning how to use programming and data analytics tools such as VBA, Python, Tableau, Power BI, Power Query, and more.
A statistical term where a small section of a population is selected to make a decision
Sampling is the method of selecting a small section of a larger group in order to estimate the characteristics of the entire group. Obtaining information from a large data set can be time-consuming, so taking sample data can be quicker and provides similar results.
For example, if a company wants to know the type of shoes that women between the age group of 25-30 would prefer to wear to the office, they could analyze a sample data set from a smaller area of the city rather than extracting data from the whole city. The result could be similar.
Sampling is a method of randomly selecting data from a population set, which will give a result that will be close or similar to the result that the whole population set would’ve given. The difference between the two results is called sample error. The best way to avoid sample error is to not derive a sample and instead look at the whole population set.
In the probability sampling method, every individual from the population has a chance of being selected as part of the sample. It will help give a result that is more indicative of the whole group.
Here are the types of probability sampling:
In the simple random method, every individual from the group has an equal chance of being selected in the sample. For example, when rolling a dice, the chance of number four being the result is 1/6 – i.e., one out of six possibilities.
In the systematic method, individuals are assigned numbers, and they are selected based on the numbers at regular intervals. For example, employees of a company are lined up in the order of the alphabet, and every 10th person is selected starting from the 6th employee. It means the 6th, 16th, 26th, 36th, and so on are selected.
Individuals in the stratified technique are divided into strata or subgroups based on certain criteria like gender, age, income, or profession. The stratified method ensures that there is representation from each of the subgroups in the sample.
For example, if there are 100 female employees and 50 male employees and the company wants to find out the gender ratio, the company will divide the employees into two subgroups based on gender. Then, they can select around 50 female and 25 male employees from the strata.
Like the stratified method, the cluster technique involves dividing the group into subgroups. The only difference is that in the stratified technique, the whole subgroup is selected at random. For example, suppose there are several offices around the country with a similar number of employees in each office. Instead of going to each office, only 3-4 offices are selected randomly to get the desired results.
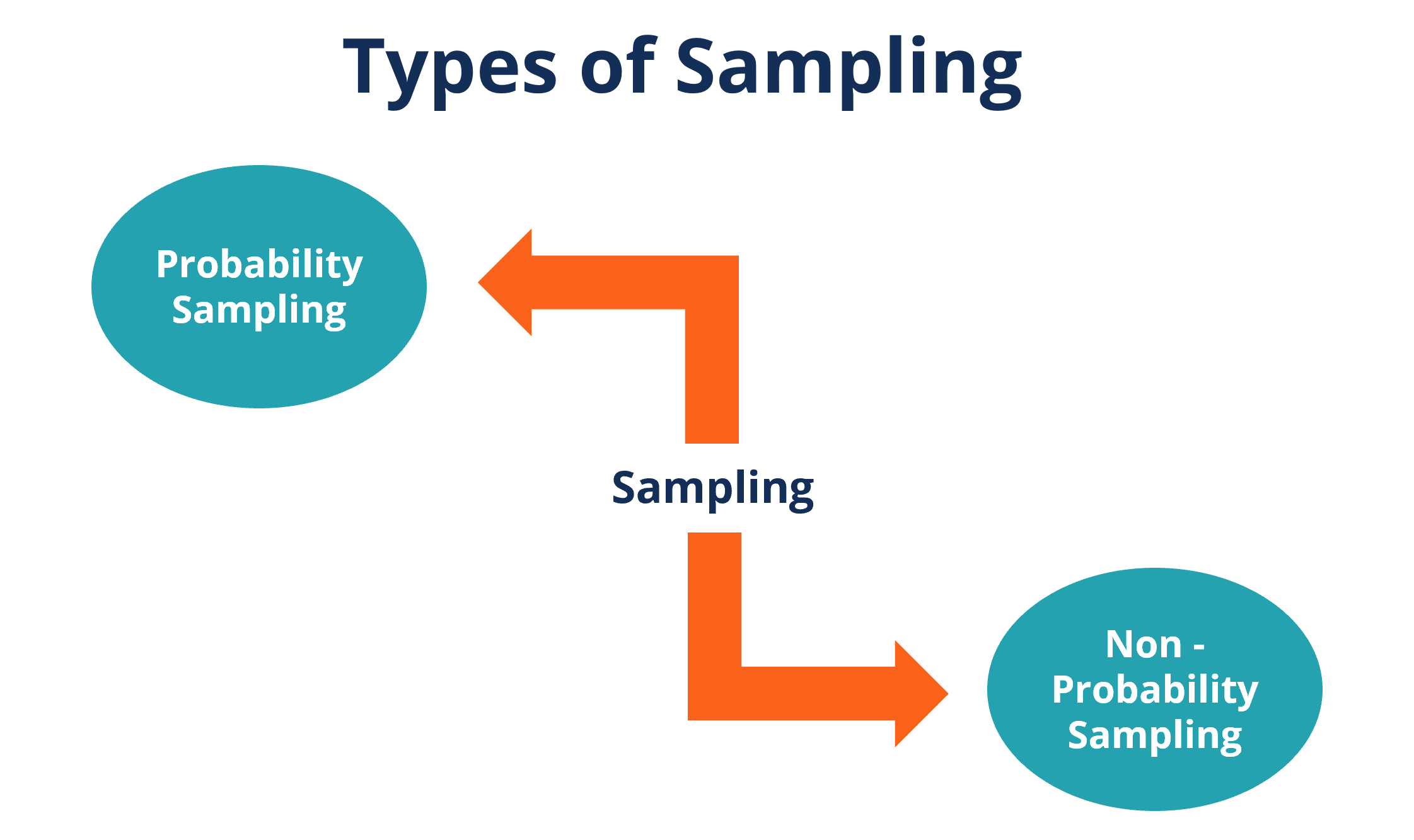
Unlike the probability method, under this method, random selection is not performed, which means not all individuals can be selected.
Here are the types of non-probability sampling:
In the convenience method, individuals who are readily available to the researcher are part of the sample. The technique is an easy, quick, and cheaper way of obtaining data. For example, a professor could ask students to complete a survey right after the lecture, as it is the most convenient way to gather information from all attendees.
In the voluntary sampling method, people volunteer to participate in the survey instead of the researcher selecting the participants. For example, a news reporter asked viewers to go to the news channel website and fill out an online survey.
In the purposive method, the researcher selects respondents who are specific to the topic of research. For example, a researcher wants to know how the university treats disabled students, so they only select students with disabilities to fill out the survey.
The snowball method is used when finding respondents is difficult. In this case, one respondent helps the researcher to get in touch with more individuals who can help in the survey. For example, if the researcher needs to find out the issues that homeless people undergo, they find one individual who can put them in touch with several other homeless people.





