Get Certified for
Business Intelligence (BIDA®)
Develop analytical superpowers by learning how to use programming and data analytics tools such as VBA, Python, Tableau, Power BI, Power Query, and more.
An algorithm that helps in reducing variance and bias in a machine learning ensemble
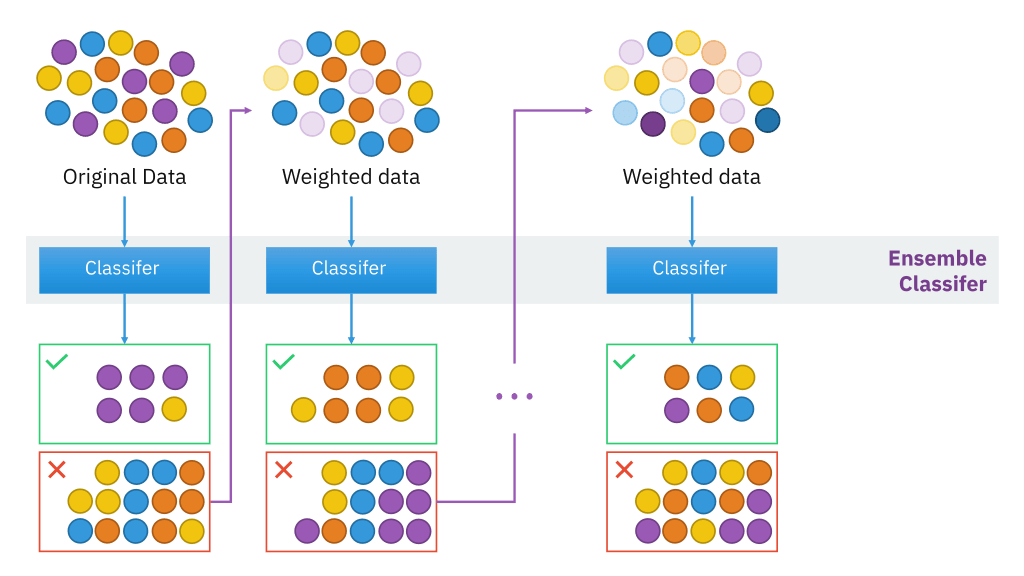
Boosting is an algorithm that helps in reducing variance and bias in a machine learning ensemble. The algorithm helps in the conversion of weak learners into strong learners by combining N number of learners.
Boosting also can improve model predictions for learning algorithms. The weak learners are sequentially corrected by their predecessors, and, in the process, they are converted into strong learners.
Boosting can take several forms, including:
Adaboost aims at combining several weak learners to form a single strong learner. Adaboost concentrates on weak learners, which are often decision trees with only one split and are commonly referred to as decision stumps. The first decision stump in Adaboost contains observations that are weighted equally.
Previous errors are corrected, and any observations that were classified incorrectly are assigned more weight than other observations that had no error in classification. Algorithms from Adaboost are popularly used in regression and classification procedures. An error noticed in previous models is adjusted with weighting until an accurate predictor is made.
Gradient boosting, just like any other ensemble machine learning procedure, sequentially adds predictors to the ensemble and follows the sequence in correcting preceding predictors to arrive at an accurate predictor at the end of the procedure. Adaboost corrects its previous errors by tuning the weights for every incorrect observation in every iteration. Still, gradient boosting aims at fitting a new predictor in the residual errors committed by the preceding predictor.
Gradient boosting utilizes the gradient descent to pinpoint the challenges in the learners’ predictions used previously. The previous error is highlighted, and by combining one weak learner to the next learner, the error is reduced significantly over time.
XGBoostimg implements decision trees with boosted gradient, enhanced performance, and speed. The implementation of gradient boosted machines is relatively slow due to the model training that must follow a sequence. They, therefore, lack scalability due to their slowness.
XGBoost is reliant on the performance of a model and computational speed. It provides various benefits, such as parallelization, distributed computing, cache optimization, and out-of-core computing.
XGBoost provides parallelization in tree building through the use of the CPU cores during training. It also distributes computing when it is training large models using machine clusters. Out-of-core computing is utilized for larger data sets that can’t fit in the conventional memory size. Cache optimization is also utilized for algorithms and data structures to optimize the use of available hardware.
As an ensemble model, boosting comes with an easy-to-read and interpret algorithm, making its prediction interpretations easy to handle. The prediction capability is efficient through the use of its clone methods, such as bagging or random forest and decision trees. Boosting is a resilient method that curbs over-fitting easily.
One disadvantage of boosting is that it is sensitive to outliers since every classifier is obliged to fix the errors in the predecessors. Thus, the method is too dependent on outliers. Another disadvantage is that the method is almost impossible to scale up. This is because every estimator bases its correctness on the previous predictors, thus making the procedure difficult to streamline.
Option trees are the substitutes for decision trees. They represent ensemble classifiers while deriving a single structure. The difference between option trees and decision trees is that the former includes both option nodes and decision nodes, while the latter includes decision nodes only.
The classification of an instance requires filtering it down through the tree. A decision node is required to choose one of the branches, whereas an option node must take the entire group of branches. This means that, with an option node, one ends up with multiple leaves that would require being combined into one classification to end up with a prediction. Therefore, voting is required in the process, where a majority vote means that the node’s been selected as the prediction for that process.
The above process makes it clear that the option nodes should not come with two options since they will end up losing the vote if they cannot find a definite winner. The other possibility is taking the average of probability estimates from various paths by following approaches such as the Bayesian approach or non-weighted method of averages.
Option trees can also be developed from modifying existing decision tree learners or creating an option node where several splits are correlated. Every decision tree within an allowable tolerance level can be converted into option trees.
To keep learning and developing your knowledge of business intelligence, we highly recommend the additional CFI resources below:






{kind=link}