Get Certified for
Business Intelligence (BIDA®)
Develop analytical superpowers by learning how to use programming and data analytics tools such as VBA, Python, Tableau, Power BI, Power Query, and more.
Situations where the variance of the residuals is unequal over a range of measured values
Heteroskedasticity refers to situations where the variance of the residuals is unequal over a range of measured values. When running a regression analysis, heteroskedasticity results in an unequal scatter of the residuals (also known as the error term).
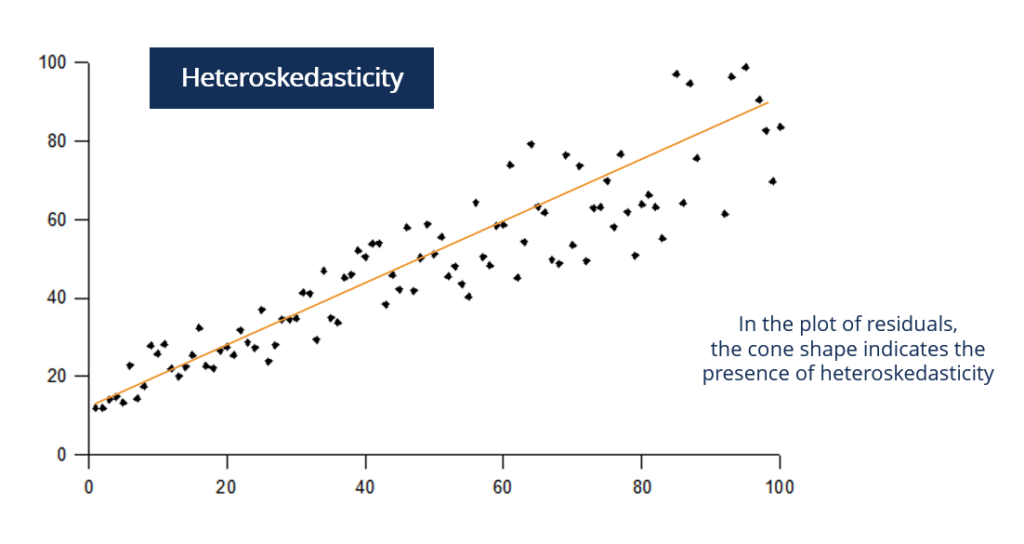
When observing a plot of the residuals, a fan or cone shape indicates the presence of heteroskedasticity. In statistics, heteroskedasticity is seen as a problem because regressions involving ordinary least squares (OLS) assume that the residuals are drawn from a population with constant variance.
If there is an unequal scatter of residuals, the population used in the regression contains unequal variance, and therefore, the analysis results may be invalid.
To look for heteroskedasticity, it’s necessary to first run a regression and analyze the residuals. One of the most common ways of checking for heteroskedasticity is by plotting a graph of the residuals.
Visually, if there appears to be a fan or cone shape in the residual plot, it indicates the presence of heteroskedasticity. Also, regressions with heteroskedasticity show a pattern where the variance of the residuals increases along with the fitted values.
When heteroskedasticity exists in a regression, it can be categorized into two types: pure and impure heteroskedasticity.
There are many reasons why heteroskedasticity may occur in regression models, but it typically involves problems with the dataset. It has been shown that models involving a wide range of values are more prone to heteroskedasticity because the differences between the smallest and largest values are so significant.
For example, suppose a dataset contains values that range from 1,000 to 1,000,000. A 10% increase in 1,000 is only 100. However, a 10% increase in 1,000,000 is 100,000. Therefore, it would be expected that larger residuals would be associated with higher values. It would cause an unequal variance of the residuals and, therefore, result in heteroskedasticity.
The concept can apply to many types of datasets where a wide range of values are expected. One example would be time-series datasets, particularly for situations where the variables change drastically over time.
For example, if you analyzed retail e-commerce sales for the past 30 years, the number of sales over the past 10 years would be significantly larger due to the recent prevalence of online shopping. It would potentially skew the residuals and result in heteroskedasticity.
Cross-sectional datasets are also prone to heteroskedasticity, as they involve a wide range of values. For example, if you were to analyze the incomes of all fast-food workers in Toronto, the range of values wouldn’t deviate too much as most fast-food workers earn close to minimum wage.
However, if you were to analyze the incomes of all workers in Toronto, there would be a wide range of values due to all the differences in salaries. It would result in an unequal distribution of values and increase the chances of heteroskedasticity.

When analyzing regression results, it’s important to ensure that the residuals have a constant variance. When the residuals are observed to have unequal variance, it indicates the presence of heteroskedasticity.
However, when the residuals have constant variance, it is known as homoskedasticity. Homoskedasticity refers to situations where the residuals are equal across all the independent variables.
If a model is homoskedastic, we can assume that the residuals are drawn from a population with constant variance. It would satisfy one of the assumptions of the OLS regression and ensure that the model is more accurate.
One common example of heteroskedasticity is the relationship between food expenditures and income. For those with lower incomes, their food expenditures are often restricted based on their budget.
As incomes increase, people tend to spend more on food as they have more options and fewer budget restrictions. For wealthier people, they can access a variety of foods with very few budget restrictions.
Therefore, there is a greater variance in food expenditures of wealthier people relative to lower-income individuals. In such a situation, the variance of the residuals is unequal across the independent variable (income). If one were to run a regression using this dataset, one would find the presence of heteroskedasticity.
Connect what you just learned to a clear career path with CFI’s role‑based courses and certification programs.
Thank you for reading CFI’s guide to Heteroskedasticity. In order to help you become a world-class analyst and advance your career to your fullest potential, these additional resources will be very helpful:





