Get Certified for
Business Intelligence (BIDA®)
Develop analytical superpowers by learning how to use programming and data analytics tools such as VBA, Python, Tableau, Power BI, Power Query, and more.
The process of preserving private or confidential information by deleting or encoding identifiers that link individuals and the stored data
Data anonymization refers to the method of preserving private or confidential information by deleting or encoding identifiers that link individuals to the stored data. It is done to protect the private activity of an individual or a corporation while preserving the credibility of the data collected and exchanged.
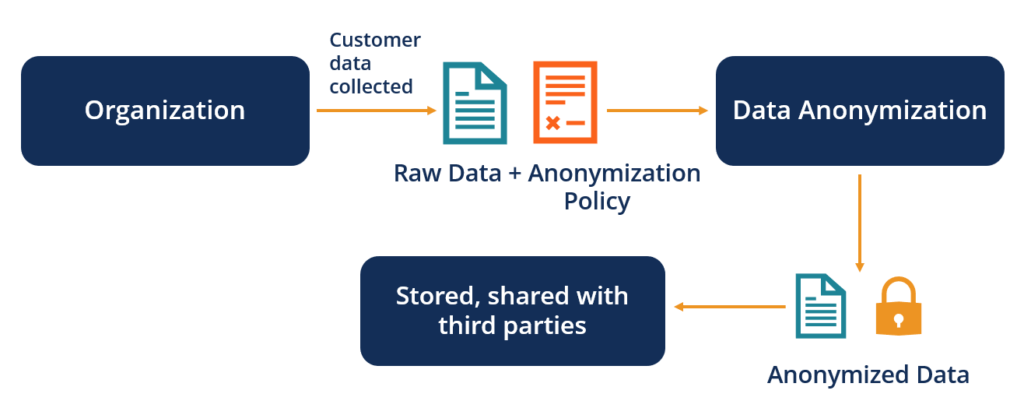
Data anonymization is one of the techniques that organizations can use to adhere to strict data privacy regulations that require the security of personally identifiable information (PII), such as health reports, contact information, and financial details.
However, even though the data of the identifiers is cleared, attackers can use de-anonymization techniques to retrace the procedure of data anonymization. As data typically flows through several sources, some of which are open to the public, de-anonymization methods will cross-reference sources and expose personal information.
Data masking refers to the disclosure of data with modified values. Data anonymization is done by creating a mirror image of a database and implementing alteration strategies, such as character shuffling, encryption, term, or character substitution. For example, a value character may be replaced by a symbol such as “*” or “x.” It makes identification or reverse engineering difficult.
Pseudonymization is a data de-identification tool that substitutes private identifiers with false identifiers or pseudonyms, such as swapping the “John Smith” identifier with the “Mark Spencer” identifier. It maintains statistical precision and data confidentiality, allowing changed data to be used for creation, training, testing, and analysis, while at the same time maintaining data privacy.
Generalization involves excluding some data purposely to make it less identifiable. Data may be modified into a series of ranges or a large region with reasonable boundaries. For example, the house number at an address may be deleted, but make sure the name of the lane does not get deleted. The aim is to remove some of the identifiers while maintaining the accuracy of the data.
Data swapping – often known as permutation and shuffling – rearranges dataset attribute values so that they do not fit the original information. Switching attributes (columns) that include recognizable values, such as date of birth, can make a huge impact on anonymization.
Data perturbation modifies the initial dataset marginally by applying round-numbering methods and adding random noise. The set of values must be proportional to the disturbance. A small base can contribute to poor anonymization, while a broad base can reduce a dataset’s utility. For example, a base of 5 should be used for rounding values like age or house number.
Synthetic data is algorithmically generated information with no relation to any actual case. The data is used to construct artificial datasets instead of modifying or utilizing the original dataset and compromising privacy and protection.
The synthetic data method includes the construction of mathematical models based on patterns contained in the original dataset. Standard deviations, linear regression, medians, or other statistical methods can be used to produce synthetic results.
Data anonymization is a method of ensuring that the company understands and enforces its duty to secure sensitive, personal, and confidential data in a world of highly complex data protection mandates that can vary depending on where the business and the customers are based. Thus, it protects companies against the possible loss of market share and trust.
Data anonymization is a safeguard against data misuse and insider exploitation risks that result in the failure of regulatory compliance.
Data anonymization also increases the governance and consistency of results. Clean, accurate data allows you to leverage apps and services and preserve big data analytics and privacy. It fuels digital transformation by providing protected data for use in generating new market value.
The regulatory compliances require websites to receive permission from users to gather personal information, such as cookies, IP addresses, and computer IDs. Gathering anonymous data and removing identities from the database would restrict the ability to extract meaningful information from the results.
Anonymized information, for example, cannot be used for targeting purposes or personalizing the user experience.
Thank you for reading CFI’s guide to Data Anonymization. To keep learning and advancing your career, the following resources will be helpful:





