Get Certified for
Business Intelligence (BIDA®)
Develop analytical superpowers by learning how to use programming and data analytics tools such as VBA, Python, Tableau, Power BI, Power Query, and more.
Selecting, transforming, extracting, combining, and manipulating raw data to generate the desired variables for analysis or predictive modeling
Feature engineering is the process of selecting, transforming, extracting, combining, and manipulating raw data to generate the desired variables for analysis or predictive modeling. It is a crucial step in developing a machine learning model.
A feature refers to one unique attribute or variable in our data set. Since data is often stored in rows and columns, a feature can often be defined as a single column.
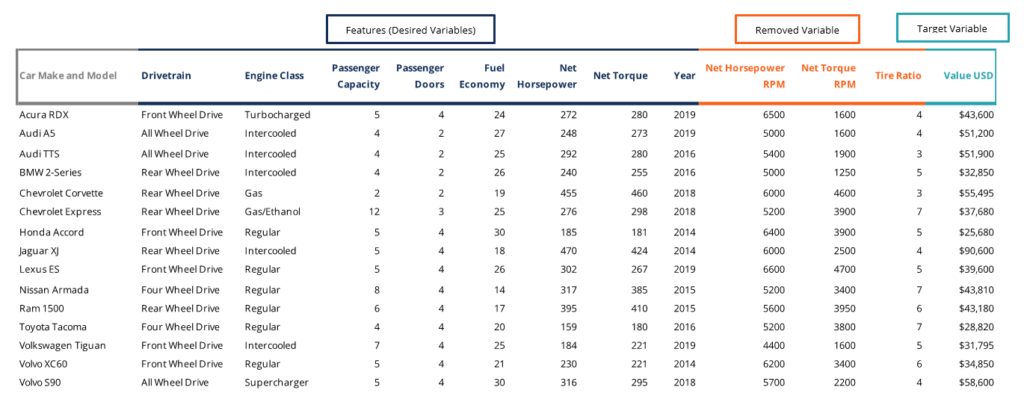
The objective of every machine learning model is to predict the value of a target variable using a set of predictor variables. Feature engineering improves the performance of the machine learning model by selecting the right features for the model and preparing the features in a way that is suitable for the machine learning model.
For example, if we would like to predict the price of a car, the target variable would be the Market Value. The predictor variables start as a long list of attributes that, through feature engineering, is slimmed down and manipulated to produce a set of effective predictor variables.
The process of feature engineering would involve questions like “Is number of seats a good predictor?” it would also involve more explanatory questions like:
As the above example conveys, feature engineering is a process that is highly dependent on the dataset and the target variables. As a result, there is no single correct method of conducting feature engineering. Feature engineering is a process that is heavily dependent on the experience and expertise of the data scientists conducting the analysis.
While there is no formula for effective feature engineering, the following five steps will provide you with insights regarding feature engineering decisions. These five steps will help you make good decisions in the process of engineering your features.
Data cleansing is the process of dealing with errors or inconsistencies in the data. This step involves identifying incorrect data, missing data, duplicated data, and irrelevant data. Moreover, Data cleansing is the process of deleting, replacing, or modifying data to remove outliers and incorrect values.
Data cleansing prepares the data to be readable by the model; this means that all missing values are appropriately handled and that all features are in the correct data type. A typical data cleansing decision can be regarding outliers. In some cases, removing outliers in the data will result in the best model, while, in other cases, the outliers should be kept as the outliers provide the model with valuable information about edge cases.

Data transformation is the process of transforming the data from one layout to another. Transformation needs to occur in a way that does not change the meaning of the original data. There are several techniques to transform the data depending on the desired outcome:
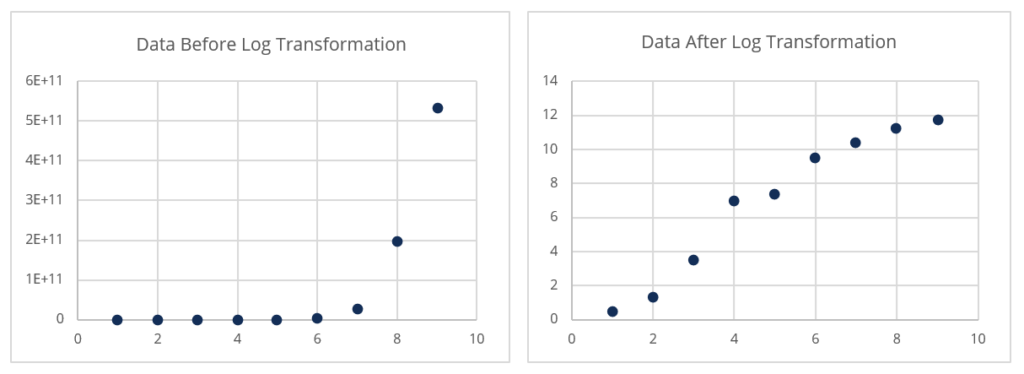
Transformation: Transformation refers to the application of a mathematical function to every data point. Transformation is a great way to handle highly skewed data.
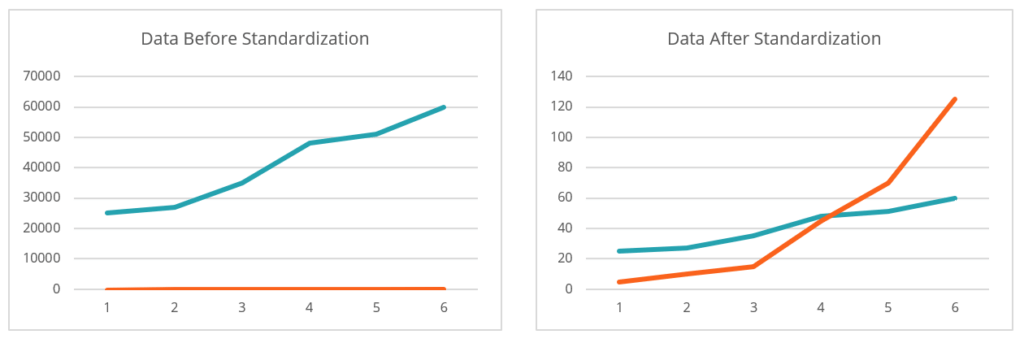
Standardization: Standardization refers to the process of converting the data into a uniform format. Data standardization is a great way of handling data with different units.
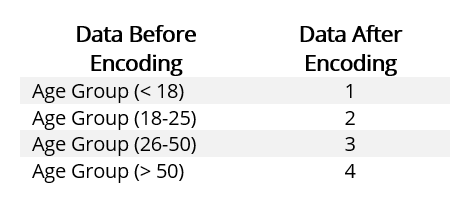
Data Encoding: Encoding refers to the process of converting categorical variables to numerical variables. Data encoding is a great way of handling nominal and ordinal variables.
 3. Feature Extraction
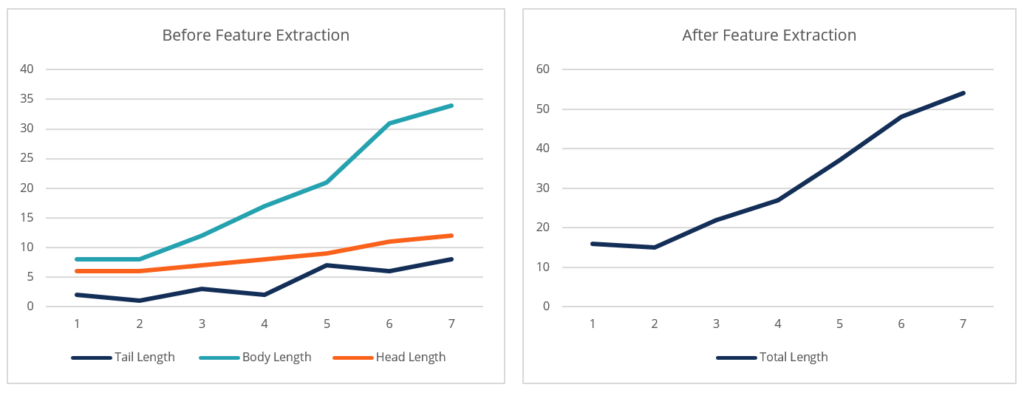
3. Feature ExtractionFeature extraction is the process of extracting new features from the existing attributes. This process is primarily concerned with reducing the number of features in the model. Feature extraction can be a lengthy process that requires the use of advanced analytics techniques (e.g., Principal Component Analysis).
However, in its essence, feature extraction answers the following question: Are the available features necessary to explain the behavior of the target variable, or can these features be aggregated and grouped in a way that maintains the effect on the target variable while reducing the number of features?
Feature extraction does not have to be complicated; it can simply be the grouping of multiple variables into a feature that measures the average of these variables.
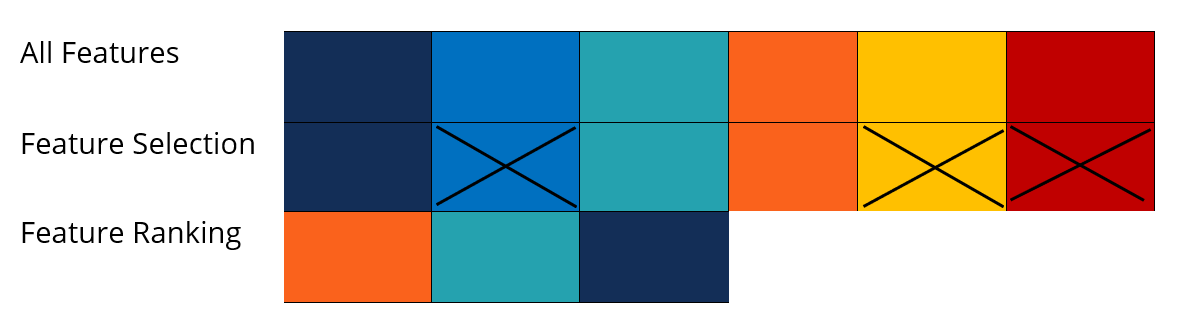
Feature selection is the process of selecting the correct subset of features to ensure that the most relevant relationship with the target variable is captured. It consists of eliminating features that do not explain the behavior of the target variable.
It can be done by ranking the features based on a statistical test to identify the most important features. It can also occur using a correlation matrix and eliminating predictor variables that are highly correlated with other predictor variables.
Feature iteration, also known as the wrapper method of feature selection, is the final step in feature engineering. It is an iterative process involving the four steps below:
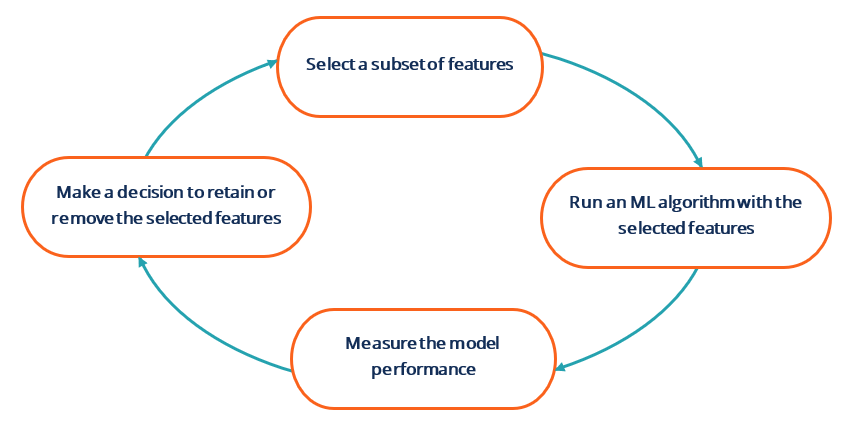
While there are several techniques and methodologies of feature iteration, they all follow a similar framework to the one identified above. Essentially, feature iteration involves adding (or removing) features from the model in a way that ensures that the features are only added (or removed) if it results in an improvement in the model’s performance.
This article has been written in collaboration with Forecast, a specialist data consultancy.
Feature engineering is an essential phase of developing machine learning models. Through various techniques, feature engineering helps in preparing, transforming, and extracting features from raw data to provide the best inputs to a machine learning model.
There is no single correct way of conducting feature engineering. However, these steps will allow data scientists to ask the right questions and make sound decisions in the process of engineering their features.
Connect what you just learned to a clear career path with CFI’s role‑based courses and certification programs.
Thank you for reading CFI’s guide to Feature Engineering. To keep learning and developing your knowledge, we highly recommend the additional resources below:





