Get Certified for
Business Intelligence (BIDA®)
Develop analytical superpowers by learning how to use programming and data analytics tools such as VBA, Python, Tableau, Power BI, Power Query, and more.
The methods, processes, and frameworks to automate some or all steps of the machine learning pipeline
AutoML (Automated Machine Learning) is a term defining the methods, processes, and frameworks to automate some or all steps of the machine learning pipeline. It offers off-the-shelf components and tools to optimize, as well as accelerate, the machine learning process. Before jumping into AutoML, it is helpful to understand the machine learning pipeline.
Machine learning consists of a series of steps, including but not limited to:
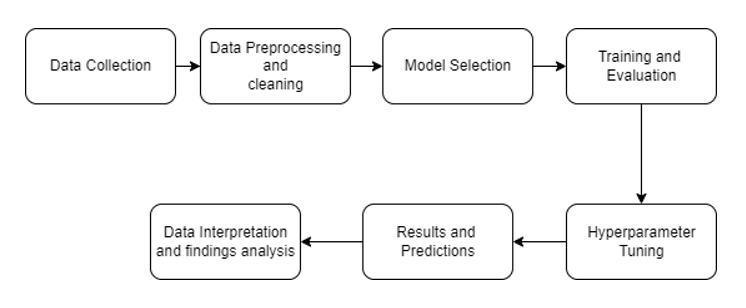
Machine learning involves training an algorithm using a set of features to make predictions. The algorithm maps input variables to output classes or labels based on some mathematical function. The performance of the machine learning model is evaluated in terms of how close the model performed compared to the truth (this can be summarized by the loss function).
The process of optimizing the algorithm so that the loss is minimized refers to training the model. This process often needs to be repeated to get to the most optimal solution, and this is where AutoML steps in.
Every dataset has its own characteristics and may perform well on a certain combination of model and hyperparameters. Determining optimal hyperparameters requires iteratively evaluating performance on different hyperparameters, as well as models. Different models may perform differently on every dataset.
Although certain heuristics and principles exist for deciding on the right combination of model and parameters, a data scientist spends an extensive amount of time in experimentation and repetitive steps to tune the hyperparameters. These repetitive steps can be automated, and this constitutes the core principle of AutoML.
Tech companies like Google, Amazon, and Microsoft are working on their own version of AutoML. For example, Google’s vastly popular AutoML is a suite of machine learning tools that enable the training of high-performing deep neural networks without the user needing any machine learning experience.
Python’s popular and widely used library, Scikit-learn, provides the functionality to automatically find the best performing machine learning pipeline for the dataset. It exhaustively tries to find the best combination of hyperparameters as well as algorithms, including even ensemble model configurations, for optimal selection. Similarly, Auto-PyTorch from Meta (Facebook) is another example from Python’s popular PyTorch library that optimizes hyperparameters and model architecture.
There exist many other similar tools and frameworks for automating entire machine learning pipelines, thereby easing the task for experts.
As the rate of Artificial Intelligence and Machine Learning adoption continues to accelerate, the requirement for efficient, fast, and accurate ML models has surged. The rapid rate of development means that reliable and state-of-the-art machine learning pipelines need to be developed around the clock.
AutoML allows data scientists to focus on more complex tasks while automation takes over the responsibility and burden of repetitive experimentation. Additionally, it assures improved performance and utility of traditional machine learning pipelines.
In recent years, the upsurge in technology has caused an increased demand for machine learning experts. The demand is far greater than the skilled people available, and thus, there has been tremendous research to bridge the gap between tech and non-tech people by introducing user-friendly software. This has led to the development of AutoML, which aims to make technology usable and implementable by non-experts.
Data scientists possess the expertise to detect and resolve any conflicts deep within the code infrastructure, which can be difficult for a computer program to imitate. Regardless, AutoML is still a plausible solution for basic implementation and collaboration on tech projects, thereby allowing wider use of technology to meet increasing demands.
Data science is a broad field, which means a data scientist needs to possess a set of different skills that cannot be completely replicated by a program or set of tools. The field requires a good understanding of the domain and requires identifying, as well as formalizing, the problem in a certain way before arriving at the possible solutions.
Real-world data is almost always noisy and messy. It consists of inconsistent labels, missing values, misspelled words, duplicates, different units, and outliers. It must be thoroughly pre-processed and prepared before applying any mathematical operations to the data.
The AutoML that has been developed so far is limited to certain problems such as classification and regression. It is not efficient enough to deal with unsupervised machine learning, which involves categorizing data after being trained with unlabelled data.
The intended aim of AutoML is to assist data scientists in their work and not replace them. It is a good option for building models and allowing non-experts to contribute to the machine learning domain. But unlike data scientists, AutoML cannot define business problems or apply domain knowledge to derive useful features from the data.
Most importantly, data scientists can draw actionable insights from data and convert data to information, which is still a difficult task for AutoML. They are well-equipped with a variety of different skill sets, allowing them to be experts in their fields. Although AutoML is an efficient and helpful tool for speeding up machine learning development, it will not be replacing data scientists any time soon.
This article has been written in collaboration with Forecast, a specialist data consultancy.
Connect what you just learned to a clear career path with CFI’s role‑based courses and certification programs.
Thank you for reading CFI’s guide to AutoML for Data Scientists. To keep advancing your career, the additional CFI resources below will be useful:





