Get Certified for
Business Intelligence (BIDA®)
Develop analytical superpowers by learning how to use programming and data analytics tools such as VBA, Python, Tableau, Power BI, Power Query, and more.
A combination of decision trees that can be modeled for prediction and behavior analysis
Random forest is a technique used in modeling predictions and behavior analysis and is built on decision trees. It contains many decision trees representing a distinct instance of the classification of data input into the random forest. The random forest technique considers the instances individually, taking the one with the majority of votes as the selected prediction.
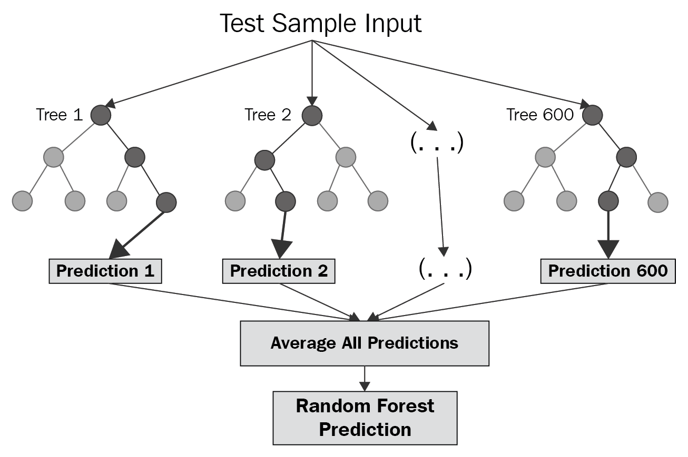
Each tree in the classifications takes input from samples in the initial dataset. Features are then randomly selected, which are used in growing the tree at each node. Every tree in the forest should not be pruned until the end of the exercise when the prediction is reached decisively. In such a way, the random forest enables any classifiers with weak correlations to create a strong classifier.
The random forest method can build prediction models using random forest regression trees, which are usually unpruned to give strong predictions. The bootstrap sampling method is used on the regression trees, which should not be pruned. Optimal nodes are sampled from the total nodes in the tree to form the optimal splitting feature.
The random sampling technique used in selecting the optimal splitting feature lowers the correlation and hence, the variance of the regression trees. It improves the predictive capability of distinct trees in the forest. The sampling using bootstrap also increases independence among individual trees.
Variables (features) are important to the random forest since it’s challenging to interpret the models, especially from a biological point of view. The naïve approach shows the importance of variables by assigning importance to a variable based on the frequency of its inclusion in the sample by all trees. It can be achieved easily but presents a challenge since the effects on cost reduction and accuracy increase are redundant.
The permutation importance is a measure that tracks prediction accuracy where the variables are randomly permutated from out-of-bag samples. The permutation importance approach works better than the naïve approach but tends to be more expensive.
Due to the challenges of the random forest not being able to interpret predictions well enough from the biological perspectives, the technique relies on the naïve, mean decrease impurity, and the permutation importance approaches to give them direct interpretability to the challenges. The three approaches support the predictor variables with multiple categories.
In the case of continuous predictor variables with a similar number of categories, however, both the permutation importance and the mean decrease impurity approaches do not exhibit biases. Variable selection often comes with bias. To avoid it, one should conduct subsampling without replacement, and where conditional inference is used, the random forest technique should be applied.
Oblique random forests are unique in that they use oblique splits for decisions in place of the conventional decision splits at the nodes. Oblique forests show lots of superiority by exhibiting the following qualities.
First, they can separate distributions at the coordinate axes using a single multivariate split that would include the conventionally needed deep axis-aligned splits. Secondly, they enable decreased bias from the decision trees for the plotted constraints. The conventional axis-aligned splits would require two more levels of nesting when separating similar classes with the oblique splits making it easier and efficient to use.
The random forest classifier is a collection of prediction trees. Every tree is dependent on random vectors sampled independently, with similar distribution with every other tree in the random forest.
Originally designed for machine learning, the classifier has gained popularity in the remote-sensing community, where it is applied in remotely-sensed imagery classification due to its high accuracy. It also achieves the proper speed required and efficient parameterization in the process. The random forest classifier bootstraps random samples where the prediction with the highest vote from all trees is selected.
The individuality of the trees is important in the entire process. The individuality of each tree is guaranteed due to the following qualities. First, every tree training in the sample uses random subsets from the initial training samples. Secondly, the optimal split is chosen from the unpruned tree nodes’ randomly selected features. Thirdly, every tree grows without limits and should not be pruned whatsoever.
Random forests present estimates for variable importance, i.e., neural nets. They also offer a superior method for working with missing data. Missing values are substituted by the variable appearing the most in a particular node. Among all the available classification methods, random forests provide the highest accuracy.
The random forest technique can also handle big data with numerous variables running into thousands. It can automatically balance data sets when a class is more infrequent than other classes in the data. The method also handles variables fast, making it suitable for complicated tasks.
Thank you for reading CFI’s guide to Random Forest. To keep learning and developing your knowledge base, please explore the additional relevant CFI resources below:





