Get Certified for
Business Intelligence (BIDA®)
Develop analytical superpowers by learning how to use programming and data analytics tools such as VBA, Python, Tableau, Power BI, Power Query, and more.
A regression method that performs variable selection and regularization simultaneously
Elastic net linear regression uses the penalties from both the lasso and ridge techniques to regularize regression models. The technique combines both the lasso and ridge regression methods by learning from their shortcomings to improve the regularization of statistical models.
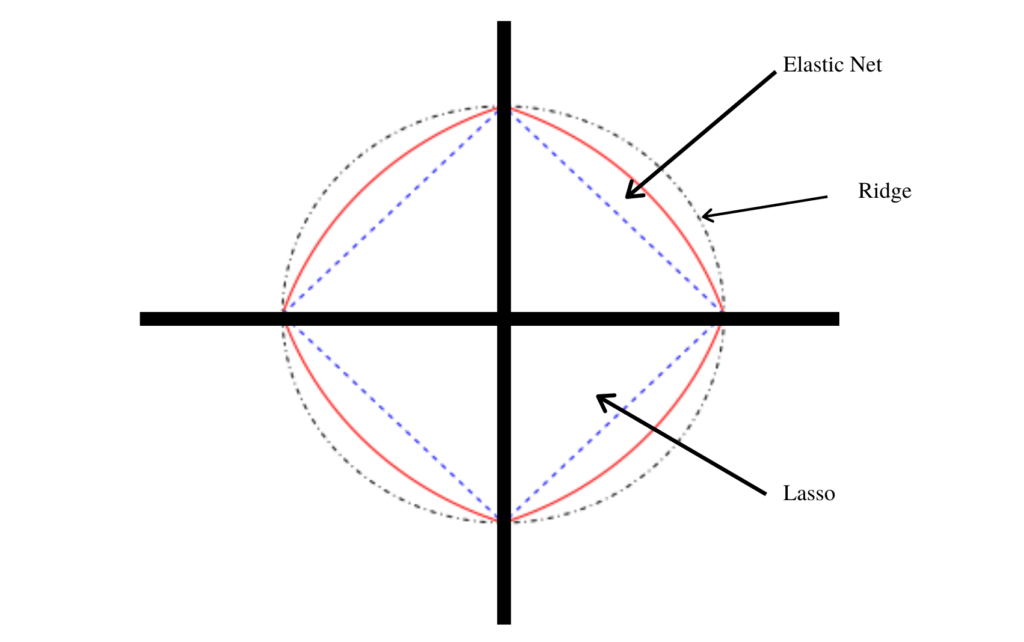
The elastic net method improves lasso’s limitations, i.e., where lasso takes a few samples for high dimensional data. The elastic net procedure provides the inclusion of “n” number of variables until saturation. If the variables are highly correlated groups, lasso tends to choose one variable from such groups and ignore the rest entirely.
To eliminate the limitations found in lasso, the elastic net includes a quadratic expression (||β||2) in the penalty, which, when used in isolation, becomes ridge regression. The quadratic expression in the penalty elevates the loss function toward being convex. The elastic net draws on the best of both worlds – i.e., lasso and ridge regression.
In the procedure for finding the elastic net method’s estimator, two stages involve both the lasso and regression techniques. It first finds the ridge regression coefficients and then conducts the second step by using a lasso sort of shrinkage of the coefficients.
This method, therefore, subjects the coefficients to two types of shrinkages. The double shrinkage from the naïve version of the elastic net causes low efficiency in predictability and high bias. To correct for such effects, the coefficients are rescaled by multiplying them by (1+λ2).
When plotted on a Cartesian plane, the elastic net falls in between the ridge and lasso regression plots since it is the combination of those two regression methods. The plot for the elastic net also exhibits singularity at the vertices, which are important for sparsity. It also exhibits strict convex edges where the convexity depends on the value of α.
Convexity is also dependent on the grouping effect dependent on the correlation of the variables selected. The higher the correlation of the variables, the higher the grouping effect, and, hence, the higher the number of variables included in the sample.
Model building requires variables selection to form a subset of predictors. Elastic net uses the p>>n problem approach, which means that the number of predictors’ numbers is higher than the number of samples used in the model. Elastic net is appropriate when the variables form groups that contain highly correlated independent variables.
Variable selection is incorporated into the model-building procedure to aid in raising the accuracy. If a group of variables is highly correlated, and one of the variables is selected into the sample, the whole group is automatically included in the sample.
CATREG is an algorithm that facilitates variables transformation, both linear and nonlinear. The algorithm utilizes step and spline functions in transforming variables either non-monotonically or monotonically in non-linear transformations. CATREG can simultaneously transform and regularize variables non-monotonically without requiring first to expand variables into basic functions or dummy variables.
Elastic net loss functions can also be termed the constrained type of the ordinary least squares regression loss function. The CATREG algorithm is incorporated into the elastic net, which improves the efficiency and simplicity of the resultant algorithm. In comparison, the elastic net outperforms the lasso, which outperforms the ridge regression in terms of efficiency and simplicity.
During the regularization procedure, the l1 section of the penalty forms a sparse model. On the other hand, the quadratic section of the penalty makes the l1 part more stable in the path to regularization, eliminates the quantity limit of variables to be selected, and promotes the grouping effect.
The grouping effect helps the variables to be easily identified using correlation, enhancing the sampling procedure. It also increases the number of variables selected. When one variable is sampled in a highly correlated group, all the other variables in that group are automatically added to the sample.
Effective degrees of freedom measures the complexity of a model. Degrees of freedom are important during the estimation or the accurate prediction of a model fitting. Degrees of freedom are also incorporated in the learning of linear smoothers. In any method related to the l1 penalty, the non-linear nature of models raises the challenge in the analysis.
Elastic net can also be used in other applications, such as in sparse PCA, where it obtains principal components that are modified by sparse loadings. The other application is in the kernel elastic net, where the generation of class kernel machines takes place with support vectors.
To keep learning and developing your knowledge base, please explore the additional relevant CFI resources below:





